
Data migration made easy with SQL Workbench/J
Have you ever faced the challenge of migrating data from one database to another, perhaps even between different DB providers? Whether you are switching from an on-premise Netweaver Portal solution to SAP BTP, from a HANA DB to PostgreSQL on SAP BTP for cost savings, changing the provider of the database or moving to a new database management system – data migration is often essential, but can also be very complex.

Why use SQL Workbench/J?
The free tool support provided by SQL Workbench/J can provide a solution to such challenges. As part of our InnovateSAP initiative, we rely on SQL Workbench/J to solve migration challenges.
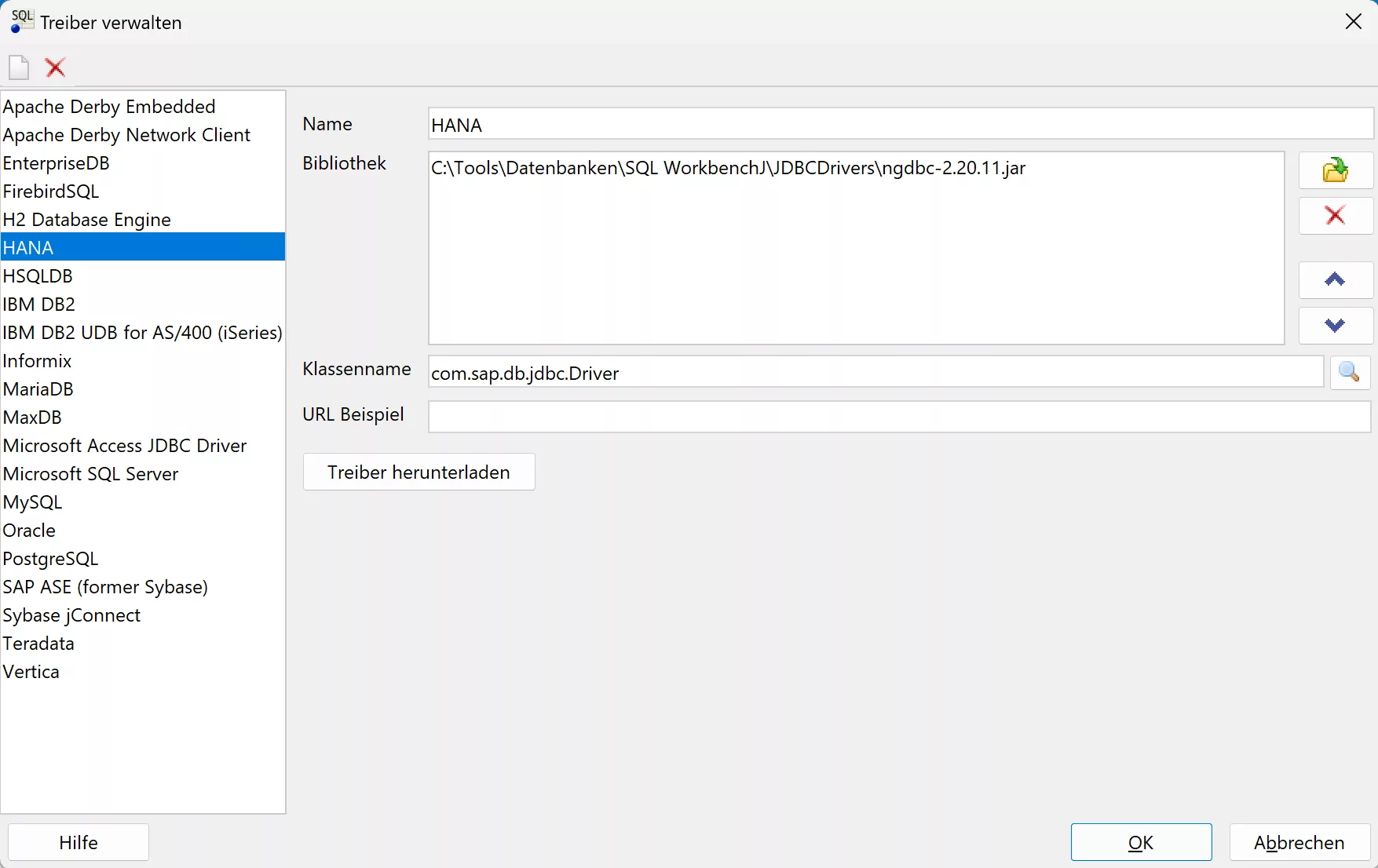
The required connection to source and target databases as well as the maintenance of predefined and additional JDBC drivers (e.g. for HANA) is relatively uncomplicated. A HANA JDBC driver has been created here:
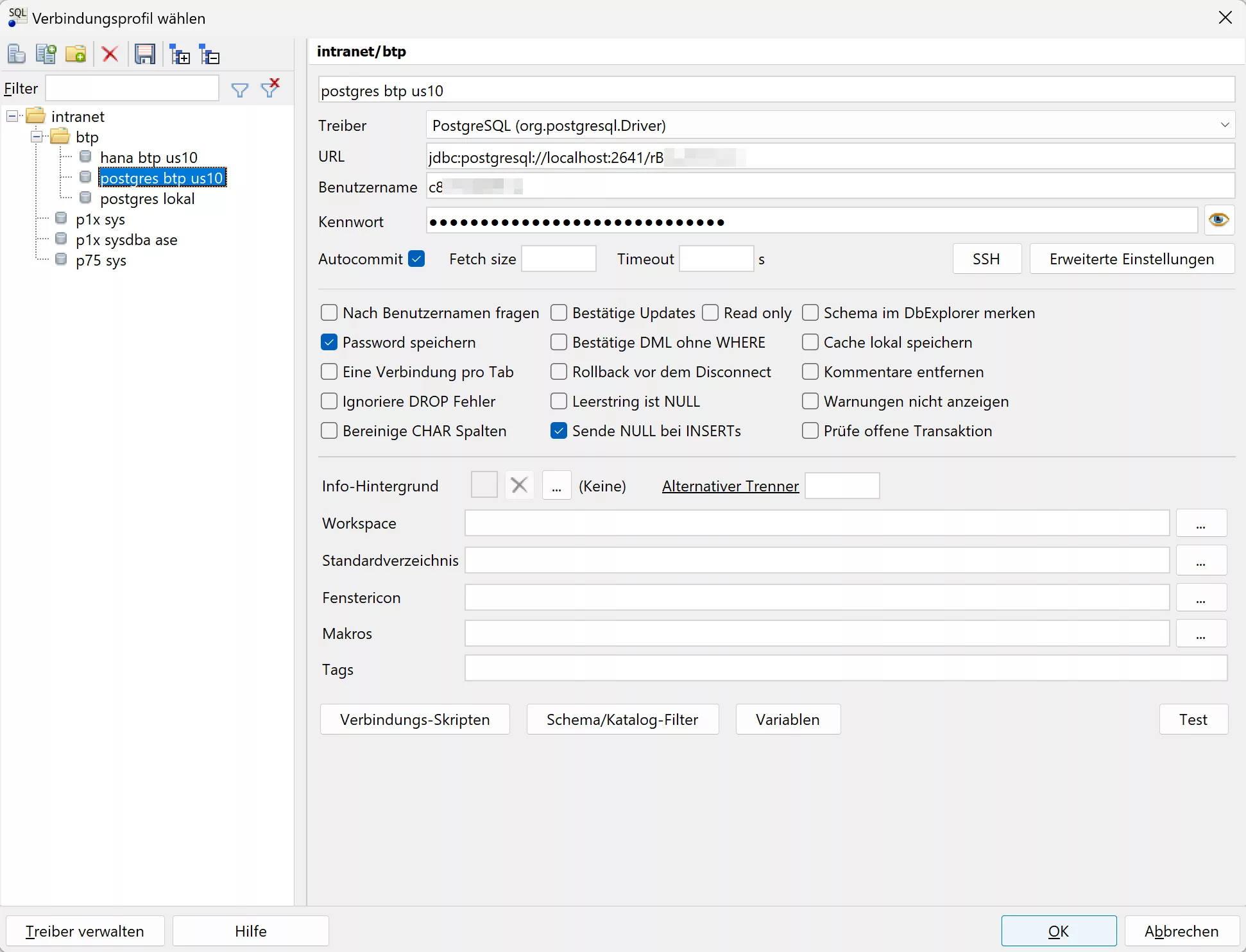
Here is a PostgreSQL connection (which uses an SSH tunnel to SAP BTP):
SQL Workbench/J supports a wide range of databases, including (sometimes more, sometimes less officially): Oracle, MySQL, PostgreSQL, SQL Server, DB2, Sybase, MS Access, Firebird, Apache Derby, HSQLDB, Informix, InterSystems Caché, MariaDB, Netezza, Pervasive PSQL, SQLite, Teradata, Amazon Redshift, Vertica, Greenplum, SAP MaxDB, Snowflake, Amazon Athena, Apache Hive, Google BigQuery, Presto, SAP HANA. This broad support makes it possible to handle virtually any data migration project in the SQL area.
Common migration hurdles
For example, one of the common challenges is blob fields (binary data of almost unlimited size) that cannot be exported as CSV, Excel or JSON with Oracle’s Oracle SQL Developer, for example. These files could become extremely large due to binary data.
In these cases, a manual export and import of files, which is already very labor-intensive, is not only error-prone, time-consuming and difficult to reproduce – it is simply impossible.
Creating Data Structures
Depending on the application, the creation of tables, indexes and, if necessary, functions can be done either via SQL directly or through your development tools. Artificial intelligence can be of particular help here, for example when creating the new data model based on the old data structure or adapting the Create SQL scripts to a new manufacturer or namespace. ChatGPT 3.5 is already a good aid here.
Implementation
With SQL Workbench/ J’s Data Pumper , you can perform data migration efficiently. Once the connections to the source and target databases have been established, the migration can be controlled with a comprehensive set of options:
- Selecting the Data Source (Table or SQL Select) and Destination – Here using SQL Source instead of a table:
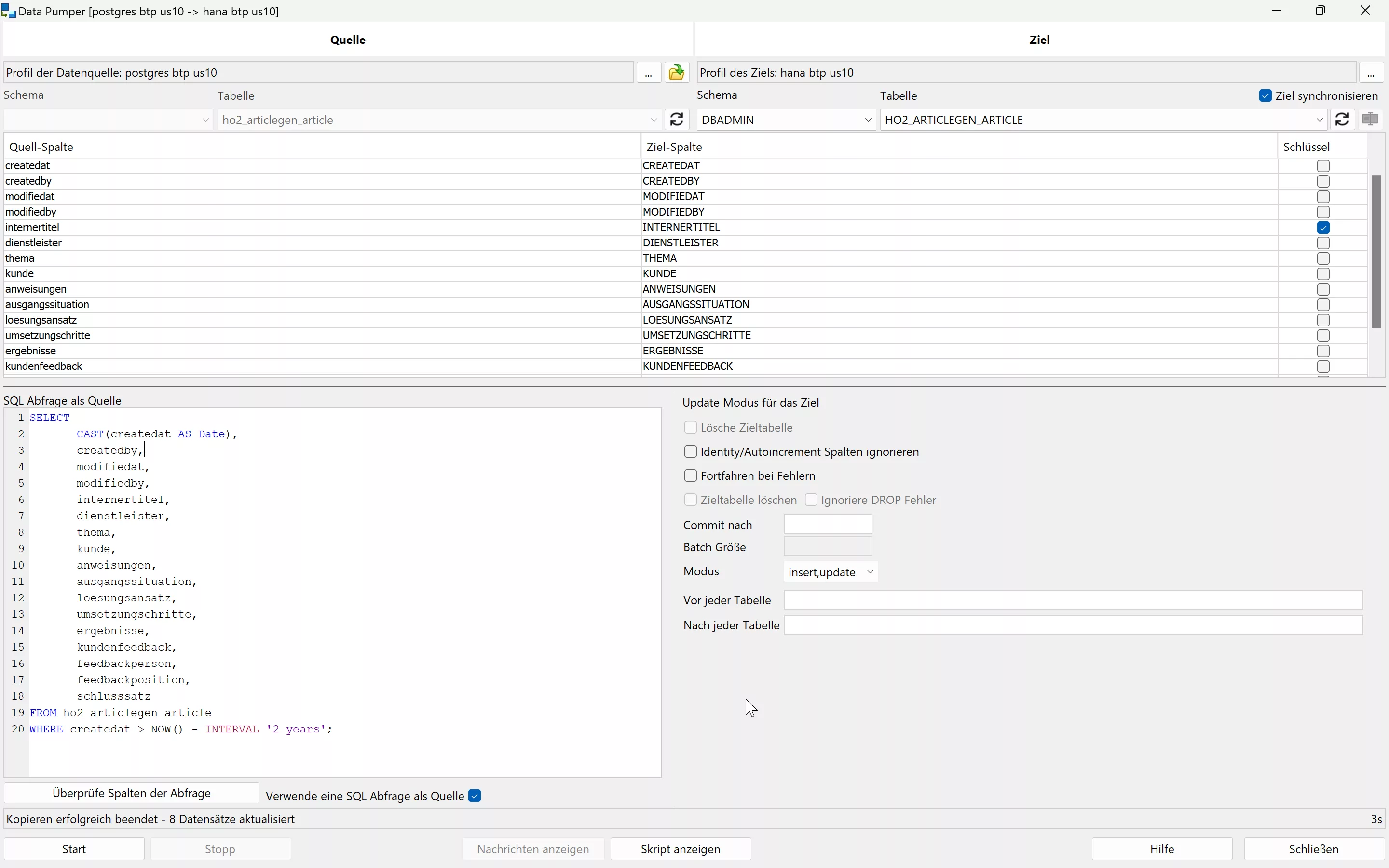
- Manual assignment of table columns, if necessary
- Specifying the Mode to Control Update/Replace Existing Values in the Target
- Setting Batch Size for Optimized Performance
A key aspect of this process is the choice of mode to determine how or if existing values should be replaced. An incorrect selection will lead to errors at runtime. Possible modes are:
- Insert
- Update
- Insert+Update
- Update+Insert
- Upsert
For performance reasons and to avoid errors, it is advisable to choose the mode that allows successful operations more frequently, i.e. insert on non-existent keys or upsert to update existing values or add new records. To ensure optimal performance, it is recommended to insert or update records in batches, typically in sizes of 100 records per batch, to avoid excessive commits.
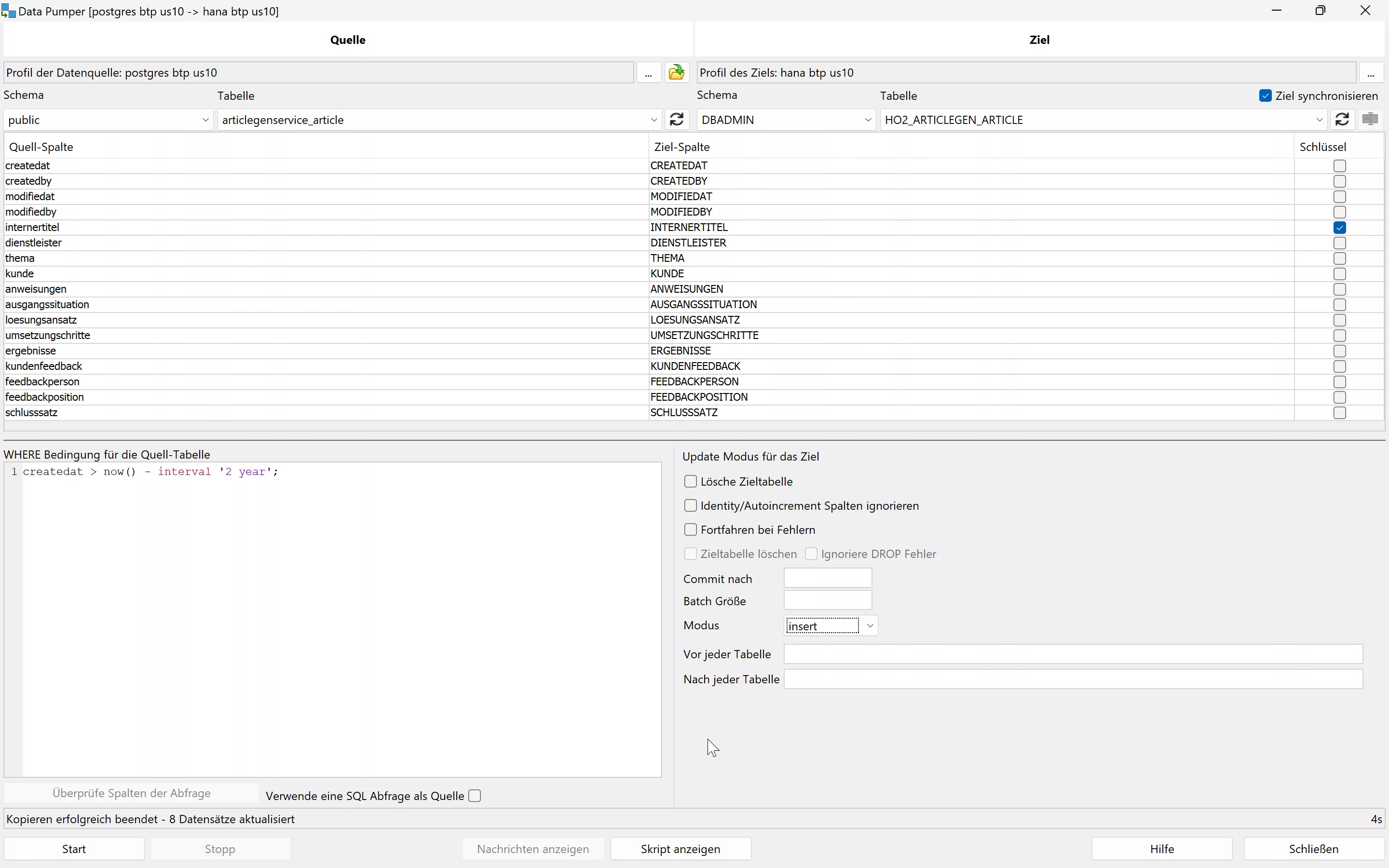
With the support of SQL Workbench/J, data can be migrated effectively and quickly.
Exportable script
To perform a data migration as scheduled, SQL Workbench/J allows you to export the Data Pumper function as a script. In this way, you can create an executable script step by step with one WB Copy command per table. The migration is then carried out at the push of a button. If necessary, normal SQL commands can also be used in the script.
Here is an example where a table is migrated from Oracle to SAP ASE (formerly Sybase SQL Server) using a SQL query and default values are set.
WbCopy -sourceProfile='p75 sys'
-sourceGroup=intranet
-targetProfile='p1x sysdba ase'
-targetGroup=intranet
-targetTable=SAPSR3DB.TCM_EMPLOYEE_DATE
-sourceQuery="SELECT ID,
CONTACT_INTERN,
IS_BACKOFFICE,
NVL(HIRE_DATE, TO_DATE('2099-01-01','YYYY-MM-DD')) as HIRE_DATE,
NVL(FIRE_DATE, TO_DATE('2099-01-01','YYYY-MM-DD')) as FIRE_DATE,
VACATION_DAYS
FROM SAPSR3DB.TCM_EMPLOYEE_DATE
"
-ignoreIdentityColumns=false
-deleteTarget=true
-continueOnError=false
-batchSize=100
;Such a script makes data migration between different database providers simple and straightforward.

Contact
We will be happy to answer any further questions you may have about data migration and the InnovateSAP initiative. If you have any challenges or specific requests, do not hesitate to contact us. Together we will find a solution!




